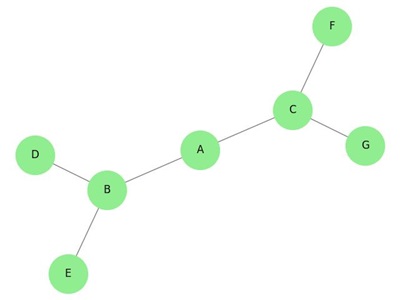
Graph
A graph ‘G’ is defined as G = (V, E) Where V is a set of all vertices and E is a set of all edges in the graph.
Example

In the above example, ab, ac, cd, and bd are the edges of the graph. Similarly, a, b, c, and d are the vertices of the graph.
Tree
A
connected acyclic graph is called a tree. In other words, a connected graph with no cycles is called a tree.
 Binary Tree
Binary Tree
Binary tree is a tree in which every node has a maximum of two nodes connected.
 Binary Search Tree
Binary Search Tree
Binary Search tree is a binary tree with the following properties.
• The left subtree of a node contains only nodes with keys less than the node’s key.
• The right subtree of a node contains only nodes with keys greater than the node’s key.
• Both the left and right subtrees must also be binary search trees.

Binary search tree should be implemented considering the above properties.
BST.h file implements the data structure and functions of Binary Search Tree.
Please find a link on github to this same implementation at the bottom.
[code]
#ifndef _BST_
#define _BST_
#include <stdlib.h>
#include <limits.h>
/*data structure binary search tree*/
typedef struct bst_node
{
int data;
struct bst_node* left;
struct bst_node* right;
}bst;
/*
allocate memory for a single
node
return the node
*/
bst* createBST();
/*
add the given data to the
given tree
*/
void addBST(bst* tree, int data);
/*
print the tree in sorted
order
*/
void printOrderedList(bst* tree);
/*
free the memory allocated
for the bst
*/
void destroyBST(bst* tree);
/*
Delete the node with
the given value from
given bst
*/
bst* deleteBST(bst* tree, int data);
/*
return 1 if given data is
present in the given bst
0 otherwise
*/
int findBST(bst* tree, int data);
/*
copy the bst given in tree
to bst given as copy
*/
void copyBST(bst* tree, bst* copy);
/*
find the node with min value
and return it
*/
bst* minValueNode(bst* tree);
/*Implementations*/
/**********************/
bst* createBST()
{
bst* tree = malloc(sizeof(bst)); // allocate memory
tree -> data = INT_MIN;
tree -> left = NULL;
tree -> right = NULL;
return tree;
}
/**************************/
void destroyBST(bst* tree)
{
if(tree == NULL)
return;
if(tree -> left != NULL)
destroyBST(tree -> left);
if(tree -> right != NULL)
destroyBST(tree -> right);
free(tree);
}
/*********************************/
void copyBST(bst* tree, bst* copy)
{
if(tree == NULL)
return;
addBST(copy, tree -> data);
if(tree -> left != NULL)
copyBST(tree -> left, copy);
if(tree -> right != NULL)
copyBST(tree -> right, copy);
}
/*******************************/
void addBST(bst* tree, int data)
{
bst* node = malloc(sizeof(bst));
node -> data = data;
node -> right = NULL;
node -> left = NULL;
if(tree -> data == INT_MIN) // if root is not entered yet
{
tree -> data = data;
return;
}
if( (tree -> data) <= data) // if data should go to left
{
if( tree -> right == NULL)
{
tree -> right = node;
}
else
addBST(tree -> right, data);
}
else
{
if( tree -> left == NULL)
{
tree -> left = node;
}
else
addBST(tree -> left, data);
}
}
/*********************************/
bst* deleteBST(bst* tree, int data)
{
bst* tmp;
if(tree == NULL)
return tree;
if(tree -> data > data)
deleteBST(tree -> left, data);
else if(tree -> data < data)
deleteBST(tree -> right, data);
else
{
if(tree -> left == NULL)
{
tmp = tree -> right;
free(tree);
return tmp;
}
else if(tree -> right == NULL)
{
tmp = tree -> left;
free(tree);
return tmp;
}
tmp = minValueNode(tree -> right); // find min node from right children
tree -> data = tmp -> data;
tree -> right = deleteBST(tree -> right, tmp -> data);//remove min node from right children
}
return tree;
}
/*********************************/
int findBST(bst* tree, int data)
{
if(tree == NULL)
return;
if(tree -> left != NULL)
{
if(findBST(tree -> left, data))
return 1;
}
if(tree -> right != NULL)
{
if(findBST(tree -> right, data))
return 1;
}
if(tree -> data == data)
{
return 1;
}
else
return 0;
}
/************************/
int findMax(bst* tree)
{
bst* tmp = tree;
int val;
while(tmp != NULL)
{
val = tmp -> data;
tmp = tmp -> right;
}
return val;
}
/************************/
int findMin(bst* tree)
{
bst* tmp = tree;
int val;
while(tmp != NULL)
{
val = tmp -> data;
tmp = tmp -> left;
}
return val;
}
/*******************************/
void printOrderedList(bst* tree)
{
if(tree == NULL)
return;
if(tree -> left == NULL && tree -> right == NULL)
{
printf("%d ",tree -> data);
return;
}
if(tree -> left != NULL)
printOrderedList(tree -> left);
printf("%d ",tree -> data);
if(tree -> right != NULL)
printOrderedList(tree -> right);
}
/***************************/
bst* minValueNode(bst* tree)
{
bst* tmp = tree;
while (tmp -> left != NULL)
tmp = tmp -> left;
return tmp;
}
#endif
[/code]
test.c file demonstrate the functionalities of the BST implemented in BST.h file.
[code]
#include <stdio.h>
#include "BST.h"
void printArray(int arr[30]);
void populate(bst* tree, int arr[30]);
/*********/
int main()
{
int randomNos[30];
int num;
bst* tree = createBST();
bst* copy = createBST();
printf("Adding random numbers to BST\n");
populate(tree, randomNos);
printf("Populated order..\n");
printArray(randomNos);
printf("Printing ordered list from tree\n");
printOrderedList(tree);
printf("\n");
printf("\n");
printf("Copying BST to another BST..\n Printing it..\n");
copyBST(tree, copy);
printOrderedList(copy);
printf("\n");
printf("\n");
printf("Max in the tree : %d \n",findMax(tree));
printf("Min in the tree : %d \n",findMin(tree));
printf("\n");
printf("Enter a number find in the tree : \n");
scanf("%d",&num);
if(findBST(tree, num))
printf("%d is in the tree\n",num);
else
printf("%d is not in the tree\n",num);
printf("\n");
printf("Removing %d from the tree..\n",randomNos[5]);
tree = deleteBST(tree, randomNos[5]);
printf("After removal\n");
printOrderedList(tree);
printf("\n");
printf("Destroying BST...\n");
destroyBST(tree);
printf("\nPrinting tree after destroy..\n\n");
printOrderedList(tree);
return 0;
}
/************************************/
void populate(bst* tree, int arr[30])
{
int i;
srand(time(NULL));
for(i = 0; i<30; i++)
{
arr[i] = rand()%50;
addBST(tree, arr[i]);
}
}
/****************************/
void printArray(int arr[30])
{
int i;
for(i = 0; i<30; i++)
printf("%d ",arr[i]);
printf("\n");
}
[/code]
Please visit here to view the code in github.